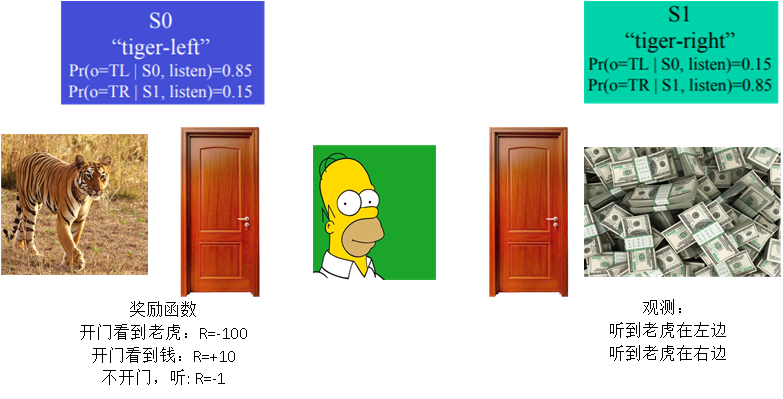
强化学习的作用
Reinforcement learning is learning what to do—how to map situations to actions—so as to maximize a numerical reward signal.
强化学习是学习做什么(决策),即基于当前的场景,学习如何做出一个可以最大化回报的动作。
深度学习与强化学习的关系
multiple layers of nonlinear processing units for feature extraction and transformation.
深度学习(DL):用多层非线性处理单元学习从输入到输出的特征提取和变换
深度强化学习(DRL):在强化学习的框架下,用深度神经网络来近似策略
基本结构

状态集:s ∈ S
动作集:a ∈ A
策略π: s => a
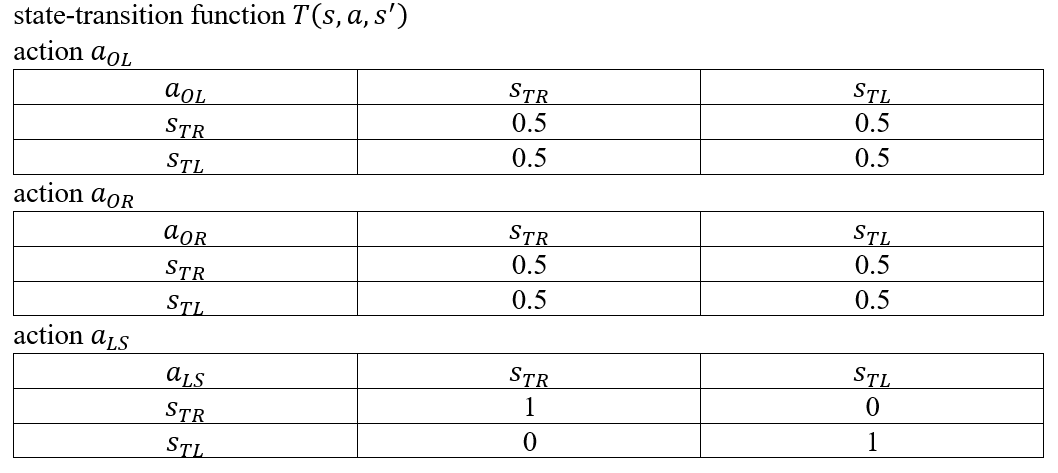
转移函数:T(s,a,s’)
或者:转移概率: P(s’|s,a)
- 奖励函数: R(s,a,s’)
MDP
策略:在状态 s 下采取什么动作 a ,找到一个最优策略 π*
π(a|s):表示策略 π 下,在状态 s 下采取行动 a 的概率
方式:通过定义每一个状态的好坏,以及或者该状态下采取某一个动作后的好坏,来寻找最优策略
价值函数
状态s,在策略π下的价值函数:
状态s,在执行动作a情况下,策略π的价值函数:
贝尔曼方程
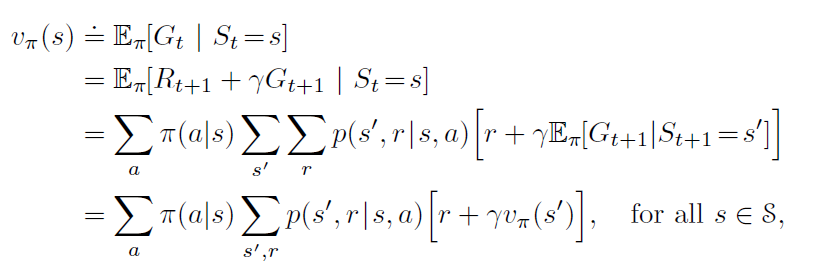
描述了当前状态下的价值函数与其下一时刻状态下的价值函数的关系
DP
“The term dynamic programming (DP) refers to a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP).”
动态规划是在给定模型情况下求解最优策略的马尔科夫决策过程的一系列算法的统称。
动态规划主要分为:策略迭代与值迭代(Policy iteration vs Value iteration)
前提条件:转移概率p(s’,r|s,a)已知
贝尔曼最优性方程:
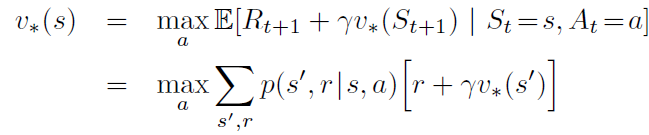
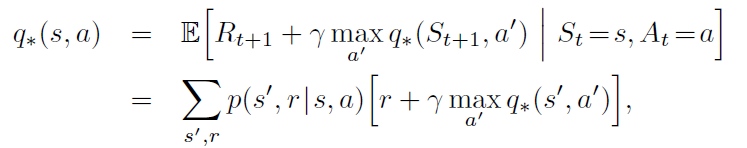
值迭代
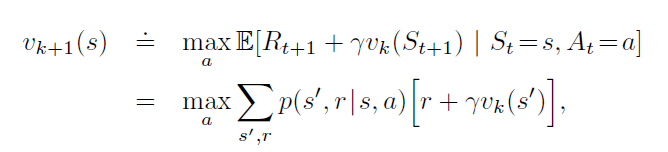
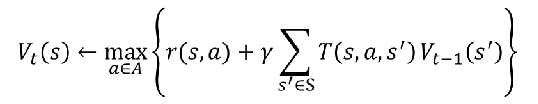

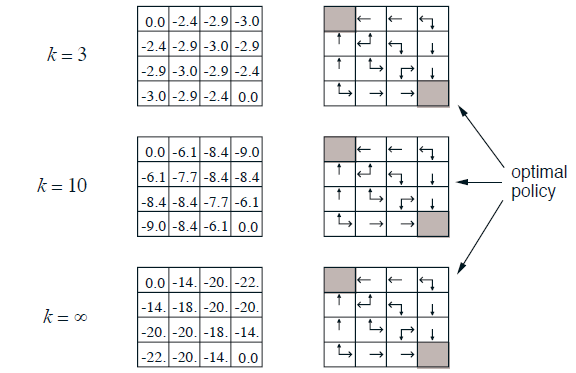
实例
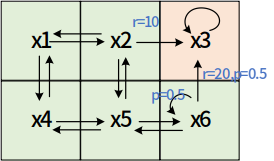
运用公式:
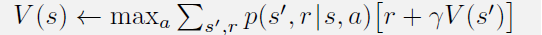
结果:

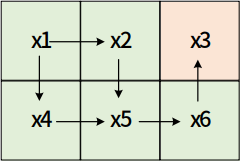
策略迭代
策略迭代=策略评估+策略提升
策略评估
目标:通过执行策略π,计算每个状态对应的状态函数值
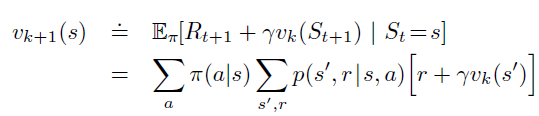

实例:

策略提升
在策略评估之后,采用贪婪策略进行策略更新
将策略改成:
则:

VI和PI的联系
策略评估:
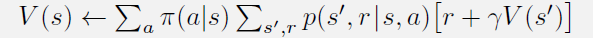
策略提升:
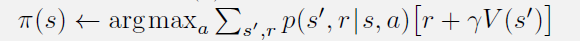
值迭代:
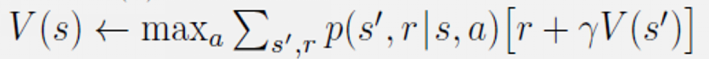
PMDP
MDP假设中,状态是完全已知的。实际生活中,由于传感器的局限性。往往难以得到当前状态的准确状态值。
但我们可以估计当前的状态分布belief: b(s)
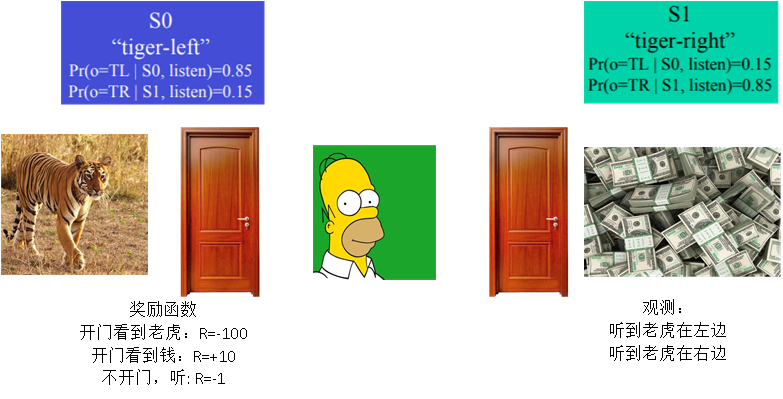
更新belief:

实例