DQN的背景
传统强化学习的局限性,无法很好的解决状态空间或者动作空间很大的实际问题
举例:小车使用相机进行导航,动作为向左,向前,向右,3种
100 x 100的灰度图片,状态数:
以现在的存储与计算能力,不可能完成
- 首先解决状态空间很大的问题
能不能根据现在的状态来估计Q(s,a)的值?

价值函数估计
假设近似器参数为w,注意有些公式给的是θ,两者是一个意思
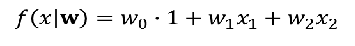
回归器的选择:
特征线性组合
神经网络
决策树
最近邻
傅里叶/小波基
DQN VS Q_learning
深度Q网络(Deep Q-Network,DQN):

Q-learning(离策略(Off-policy)TD控制):
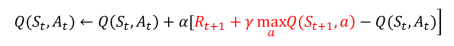
Q learning学习目标:
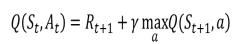
Q函数近似的学习目标:
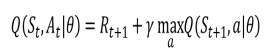
θ可以是任何回归器的参数,如果特指深度神经网络,那么我们也称之为深度Q网络
深度Q网络(Deep Q-Network,dqn)
1、如何通过神经网络进行近似
端到端的形式
输入:状态或者观测
输出:Q值
2、与监督学习的异同?
不用人工标注,神经网络生成
目标值

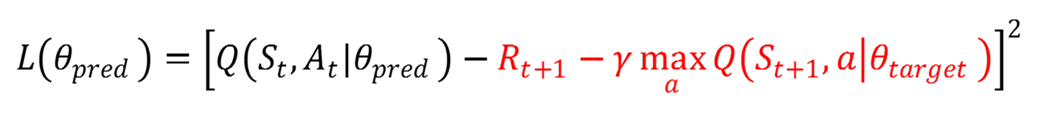
1、数据怎么来?
使用当下策略生成。
2.、有没有问题?
相邻两次的更新使用的样本是是相关的
Q(s1,a1)=0.9, 估计成了1.0, s2与s1很相似
Q(s2,a1) = 0.05+1*0.99=1.04,s3与s2很相似
……
3 、在训练时,打散训练样本的顺序
经验回放
定义一个replay buffer,RB, 记录下前N次的rollouts
在训练的时候,随机采样,进行训练

DQN with experience replay :
