时序差分学习(Temporal-Difference Learning, TD learning)是强化学习中最核心与最著名的思想
‘If one had to identify one idea as central and novel to reinforcement learning, it would undoubtedly be temporal-difference (TD) learning.’ —Richard S. Sutton& Andrew G. Barto
TD = DP + MC
TD, DP都是使用下一时刻的状态函数来估计当前时刻的状态函数。
TD,MC都是通过经历一次一次与环境互动,产生多个episode来估计状态函数。
TD:
MC:
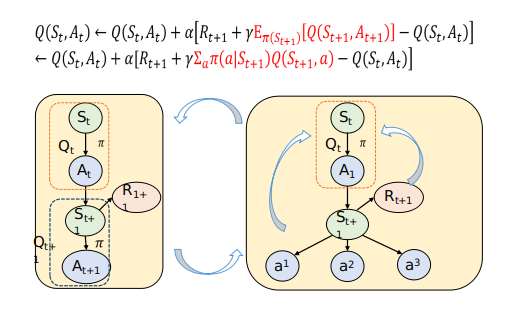
Sarsa
在策略(On policy)TD控制
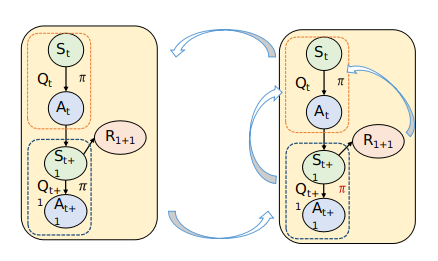

Expected Sarsa
离策略(Off-policy)TD控制
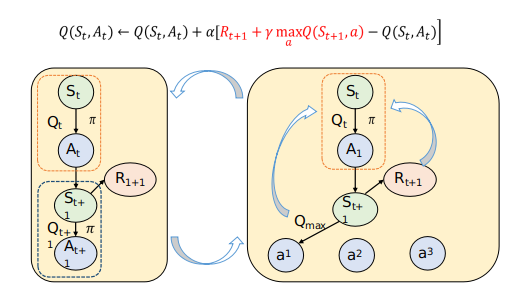
Q-learning
离策略(Off-policy)TD控制

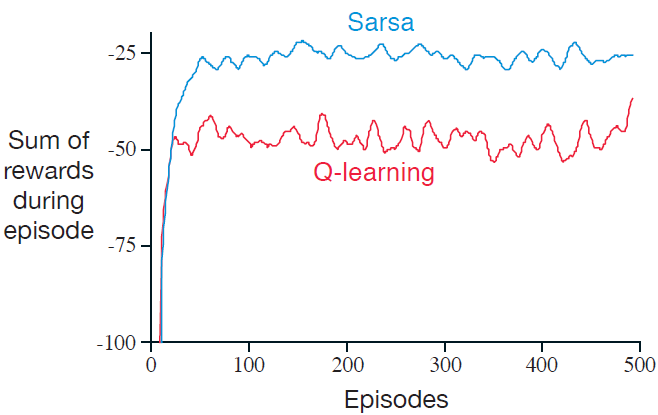
Q-learning vs Sarsa
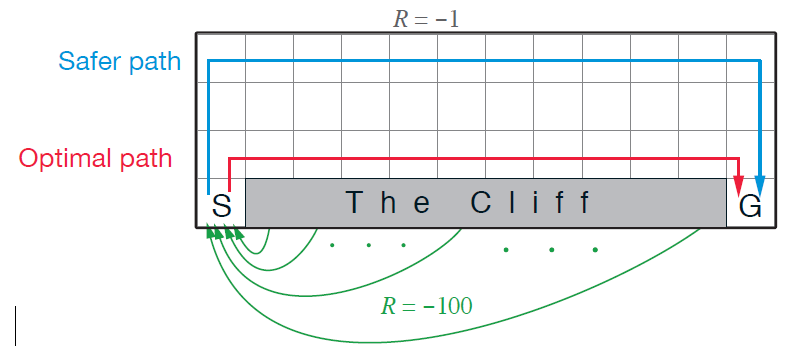
例子:悬崖行走(固定的ε=0.1)
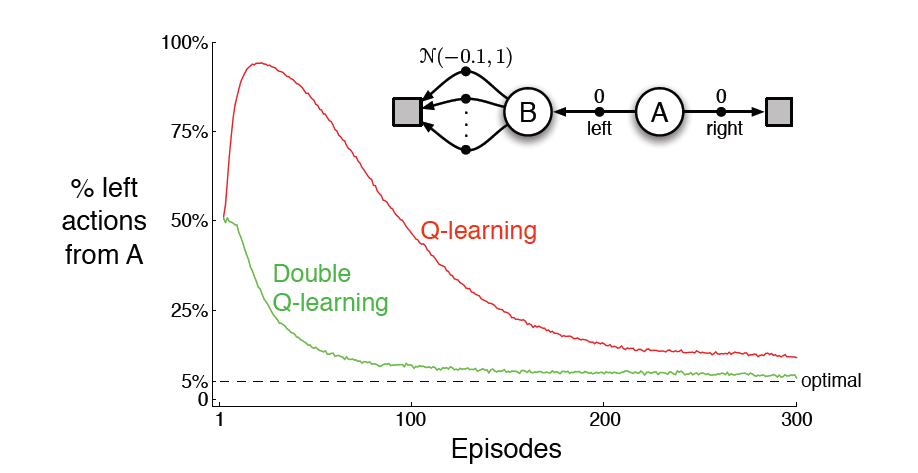
Q-learning的问题
过估计(overestimate),因此产生了Double Q learning

Double Q learning
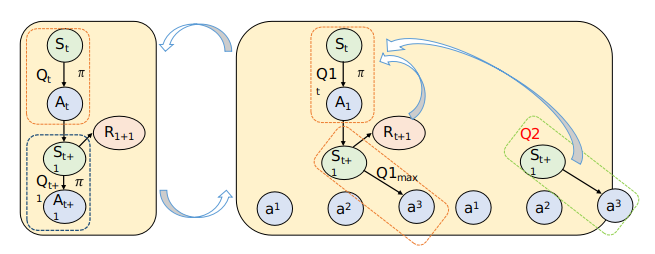

Q learning vs. Double Q learning
训练参数:ε=0.1,α=0.1, γ=1