MC
如何在没有模型的情况下评估一个策略?
如何计算V(s)和Q(s)?
通过采样的方式
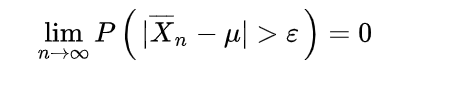
如何得到数据?
- On policy: 使用当下的策略生成的数据进行策略评估
- Off policy: 使用其他策略生成的数据进行策略评估
首次访问蒙特卡洛预测(评估):

Every-Visit Monte-Carlo Policy Evaluation:

Incremental Mean:
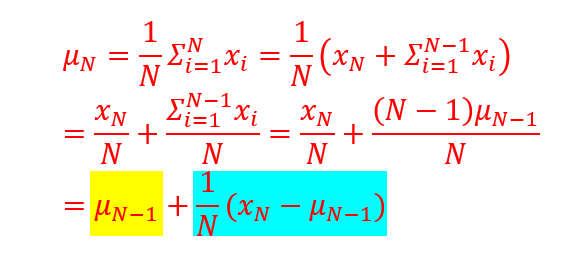
Incremental Monte-Carlo Updates

随机策略
在预测完成当前策略下的V和Q之后,我们需要对当下的策略进行改进
可以采用完全贪婪的策略提升吗?

s4->s3; s3->s2;s2->s2;s2->s1;
s4->s3; s3->s2;s2->s1;
V(s),Q(s,a)
0,1,1,1,0,0,0
Q(s2,a=左)= Q(s3,a=左)= Q(s4,a=左)=1,Q(s4,a=右)=0
一直向左走?
ε-贪婪(greedy)策略
目的: Exploration(探索)与Exploitation(利用)
ε∈(0,1),随着时间的推移逐渐减小直至0
产生一个(0,1)的随机数m
如果ε>m
采取随机策略,例如一共4个动作,那么选每一个动作的概率都是 0.25
如果ε<m
采取贪婪策略,计算当前网络所有输出值Q(St,a),选择使得Q(St,a)最大的那个at值作为下一步的动作
On-pokicy first-visit 蒙特卡洛方法:

重要性采样

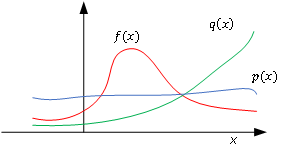
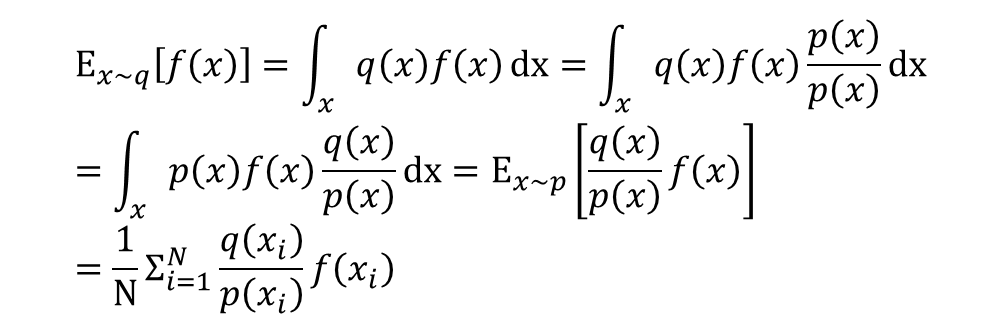
一个特定的回合内,其生成的轨迹概率:
轨迹: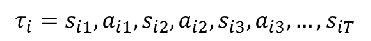
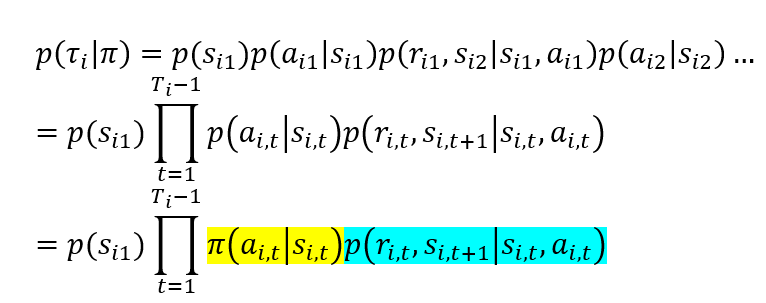
重要性采样比率:
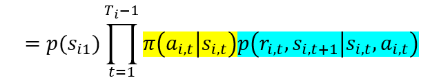
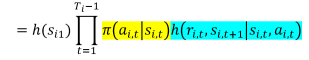
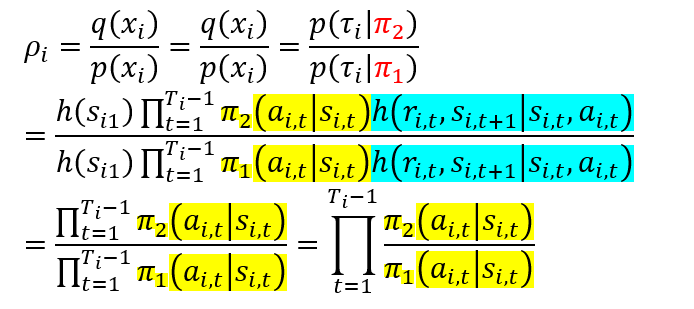
使用重要性采样的蒙特卡洛方法:
