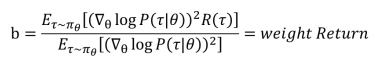TD3
TD3 = Twin Delayed DDPG:三点改进:
改进1
Twin:有两个Q值预测网络,使用输出Q值较小的那个用作计算TD error的目标值;
Double DQN:
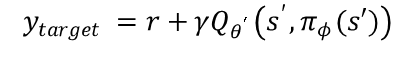
Double q learning(Q值来自于神经网络):
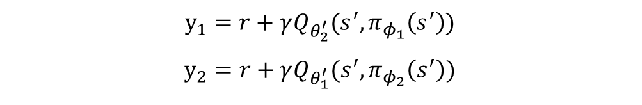
Clipped Double Q-learning algorithm:
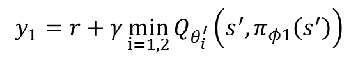
改进2
Delayed:更新策略的频率要小于更新Q值,即训练actor网络的次数要小于训练critic网络;
在值网络估计不准确的情况下(TD error很大),更新策略会引发
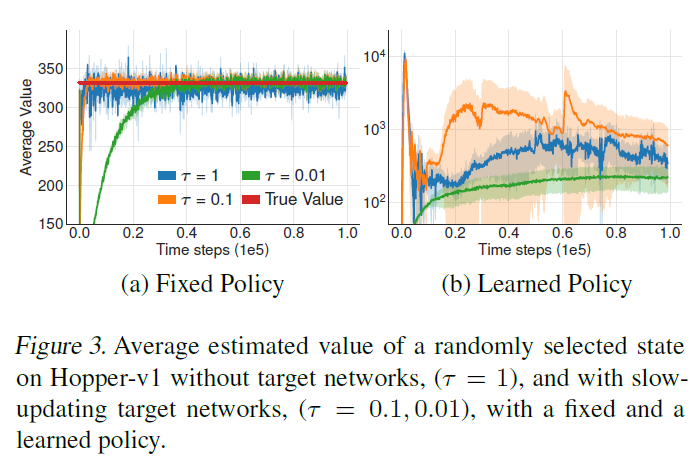
在更新critic网络d次之后再更新actor网络
改进3
目标策略平滑:
Idea:相似的动作在同一个状态下的Q值也相似
Trick:
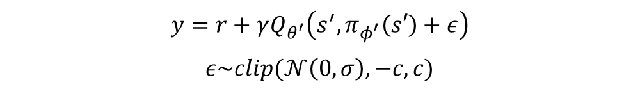
过程

效果
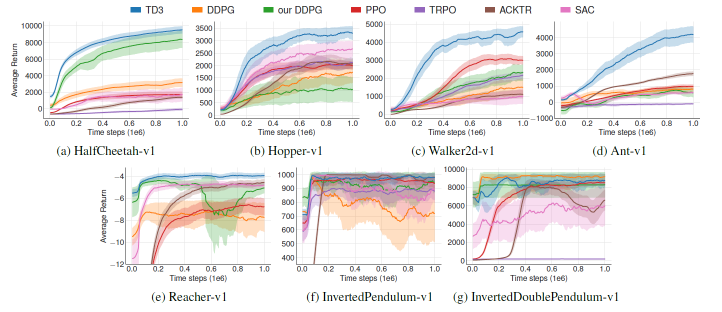
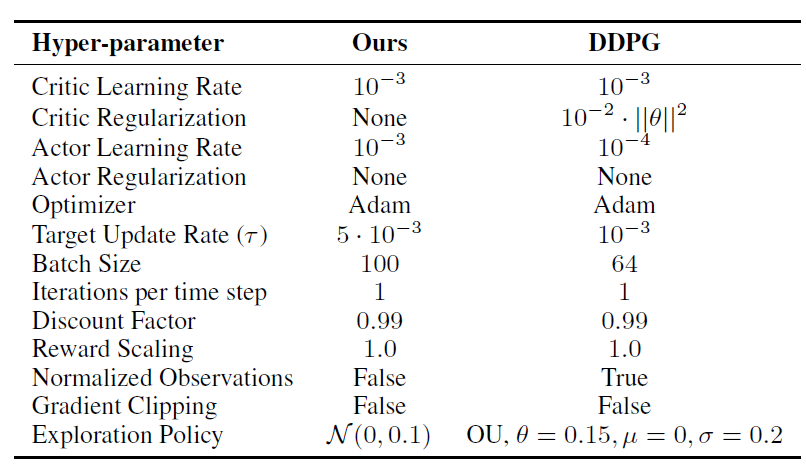
TD3 vs DDPG 参数设计
PG
一个特定的回合内,其生成的轨迹概率
轨迹:
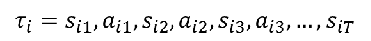
概率:
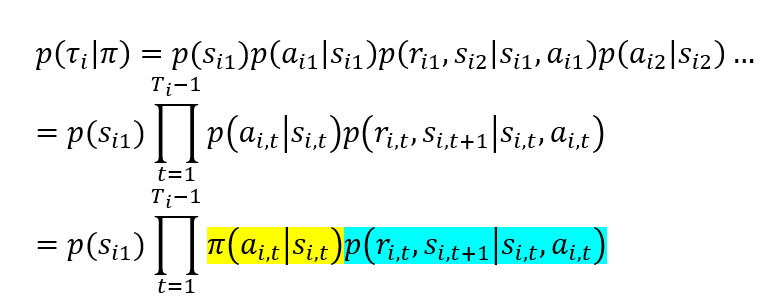
重要性采样比率:
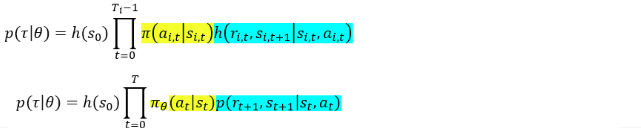
梯度公式:
*
带入求导:
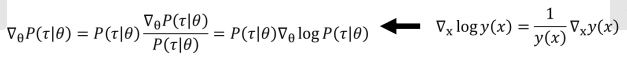
又:
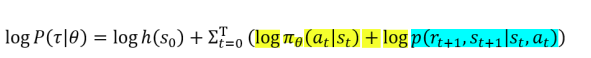
所以:
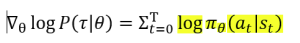
所以:
过程

蒙特卡洛估计方差太大,见下图:
使用神经网络来估计Q值
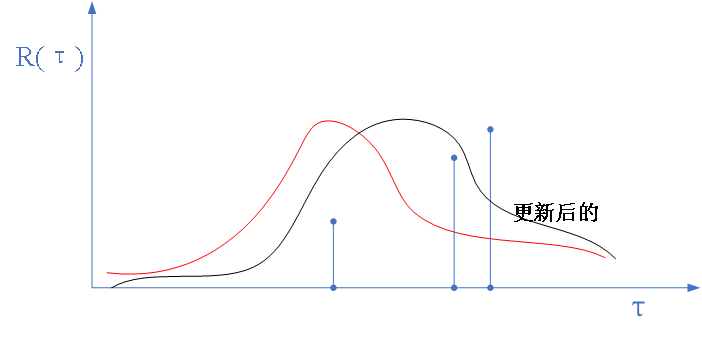
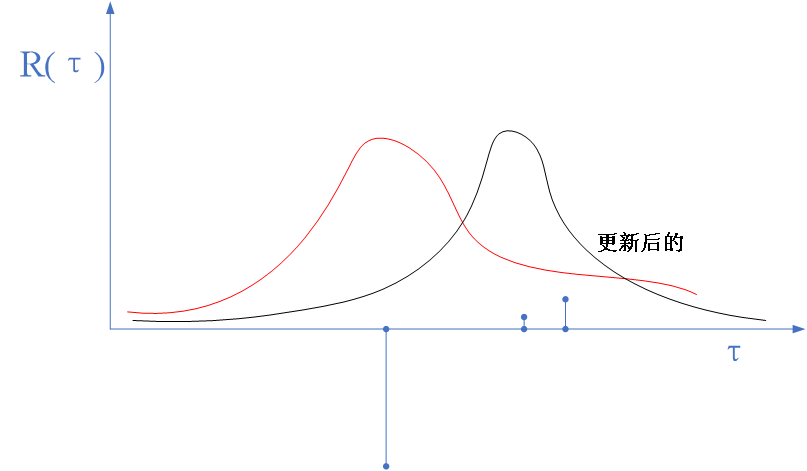
从上图看出负的噪声影响很大,怎么办呢?
可以增加一个b值补偿
推导:

方差公式和梯度公式:
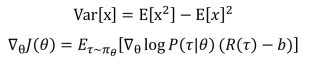
梯度公式带入方差公式:
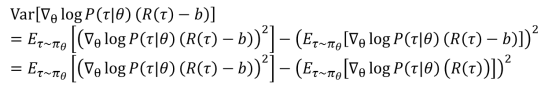
求导:
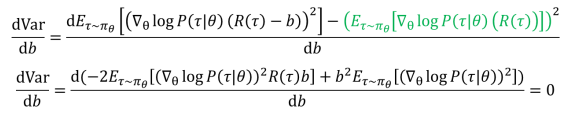
所以: