参考资料
Reinforcement Learning: An Introduction
http://incompleteideas.net/book/the-book-2nd.html
Dave Silver强化学习课程
http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html
PG
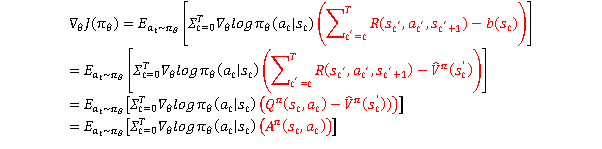
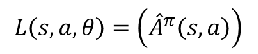


AC

PPO
近端策略优化(Proximal Policy Optimization,PPO)
https://spinningup.openai.com/en/latest/algorithms/ppo.html
PPO的优点:
VGP:在线采样,在线更新,采样完成的数据用来更新一次,因为更新过一次之后,策略就发生了改变(策略评估只能使用当下的策略生成数据),样本利用率低,效率低。
PPO:在线采样,离线更新,采样完后的数据可以用来多次更新网络,样本利用率高,效率高。
如何用之前的策略生成的数据评估当下的策略,重要性采样!
重要性采样
因为:
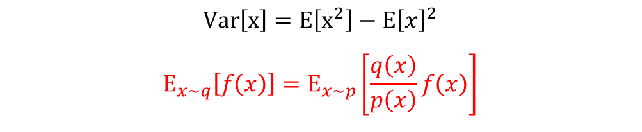
所以期望:
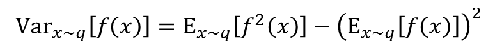
方差:
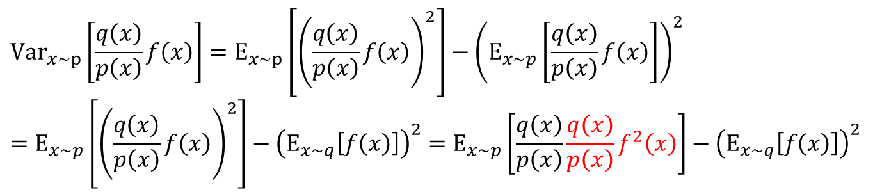
可见:
重要性采样(提高数据利用率)+约束策略变化幅度(减少方差):
PPO:
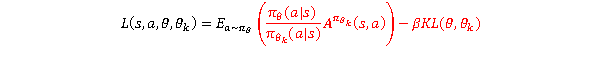
TRPO:
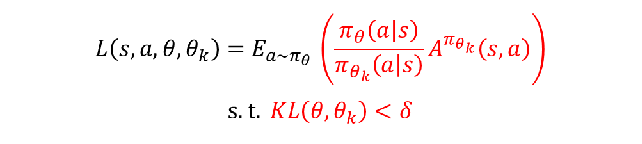
PPO-Clip
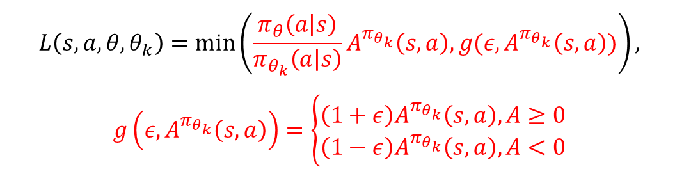
当优势值为正:
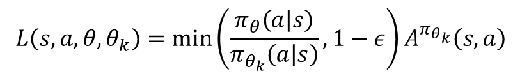
当优势值为负:
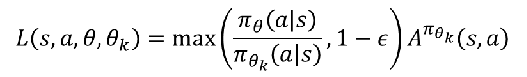

IT
正向强化学习中,所有的agent都是从头学习,其劣势有:
1:需要由专家给出合理的奖励函数,很难对复杂的动作给出一个合适的奖励动作,例如飞机特技表演。
2:比较耗时,需要训练成百上千个回合,并且有很多情况下,真实环境不具备这样的训练条件(不安全,价格昂贵),例如手术机器人学习动手术。
怎么办?
由专家进行演示,让学习者进行模仿
模仿学习(Imitation Learning):
1:直接法:直接学习策略
监督式学习:行为克隆 Behavior Cloning
2:间接法:学习奖励机制
逆向强化学习(Inverse reinforcement learning)
直接法
监督式学习:行为克隆+Data Augmentation

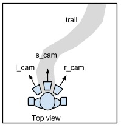

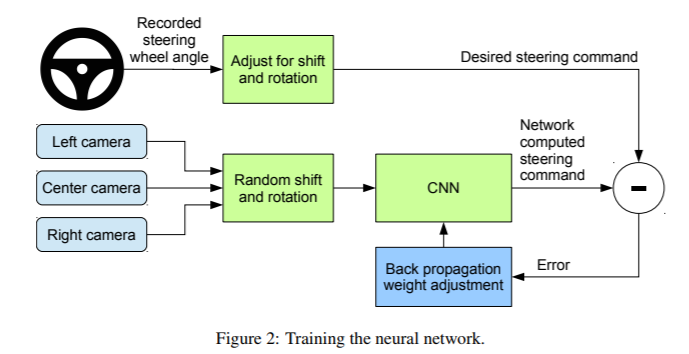
间接法
学习奖励机制。
逆向强化学习IRL,从专家轨迹中推测专家这样做的动机。
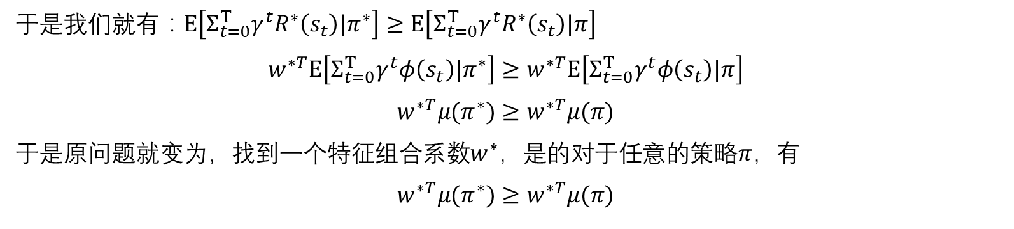

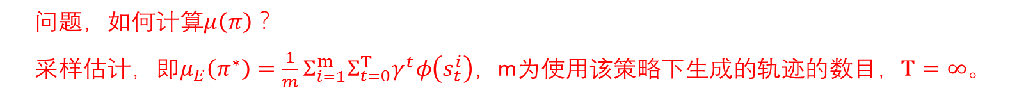
Max-margin 分类器(SVM)

http://www.andrew.cmu.edu/course/10-703/slides/Lecture_Imitation_supervised-Nov-5-2018.pdf
Apprenticeship Learning学徒学习
