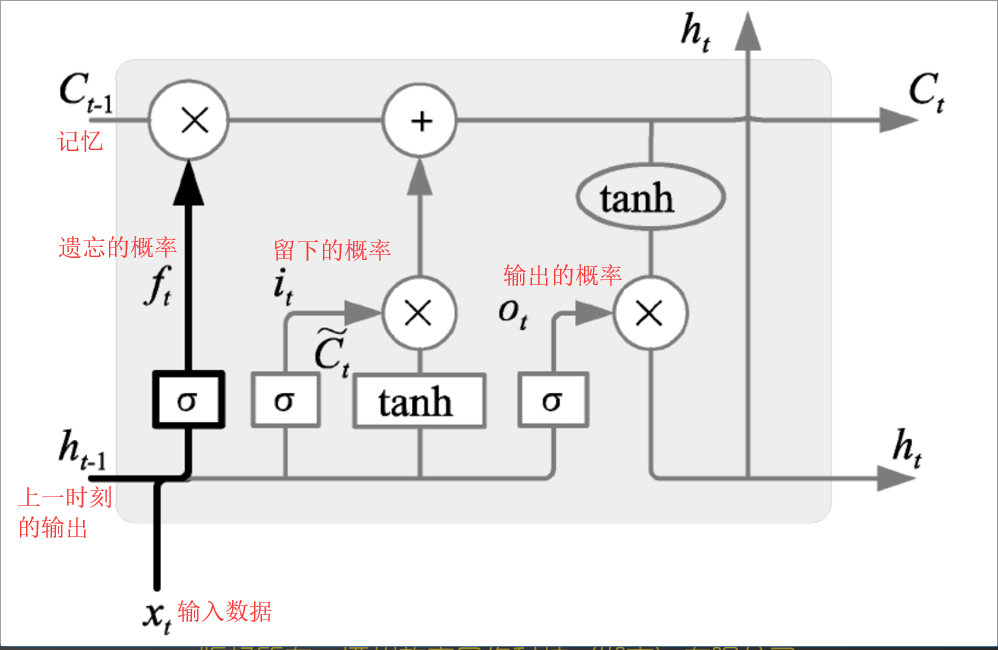
LSTM模型
LSTM(Long Short-Term Memory)是长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。
就是所谓的该记得会一直传递,不该记得就被“忘记”。
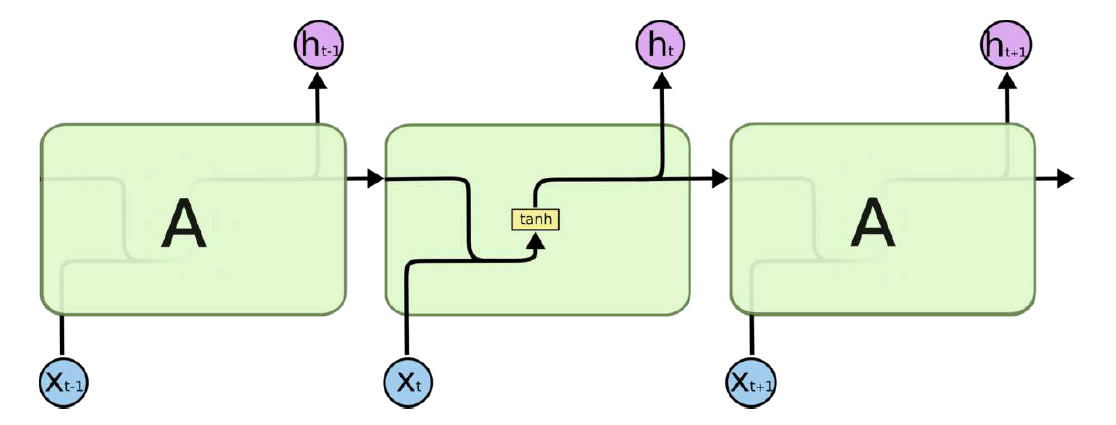
“记忆细胞”变得稍微复杂了一点
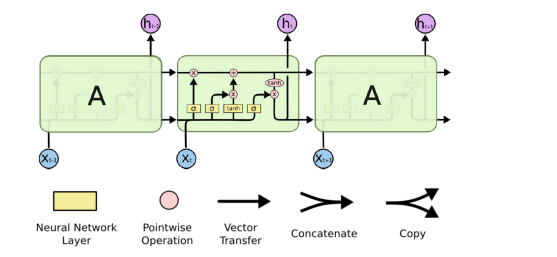
细胞状态
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传会很容易保持不变。
LSTM控制“细胞状态”的方式:
- 通过“门”让信息选择性通过,来去除或者增加信息到细胞状态。
- 包含一个
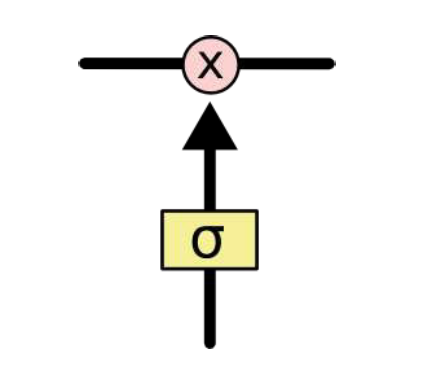
SIGMOD神经元层和一个pointwise乘法操作。 SIGMOD层输出0到1之间的概率值,描述每个部分有多少量可以通过。0代表“不许任何量通过”,1就表示“允许任意量通过”。
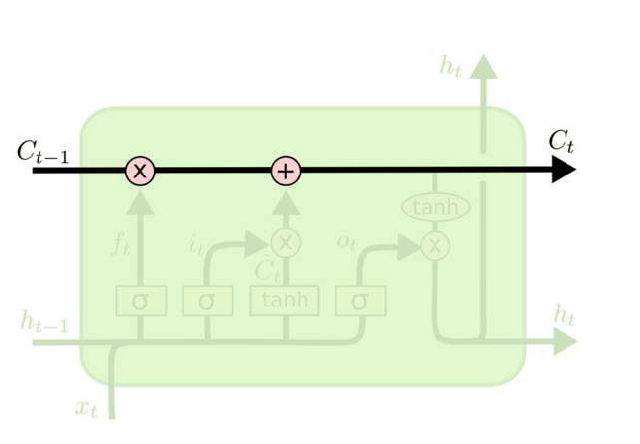
遗忘门
遗忘门(forget gate)顾名思义,是控制是否遗忘的,在LSTM中即以一定的概率控制是否遗忘上一层的隐藏细胞状态。遗忘门子结构如下图所示:
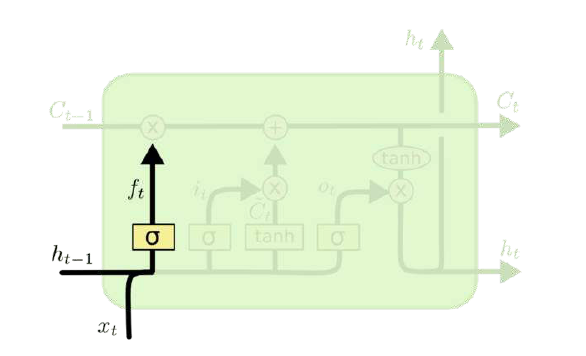
图中输入的有上一序列的隐藏状态和本序列数据,通过一个激活函数,一般情况下是SIGMOD,得到遗忘门的输出$f_t$。由于SIGMOD的输出$f_t$在[0,1]之间,因此这里的输出$f_t$代表了遗忘上一层隐藏细胞的概率。
数学表达式:
其中:$W_f、U_f、b_f$为线性关系的权重项和偏置项,σ为SIGMOD激活函数。
输入门
输入门(input gate)负责处理当前序列位置的输入,它的子结构如下图:
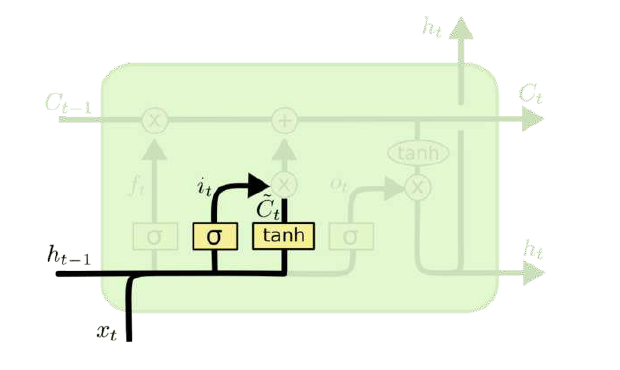
从图中可以看到输入门由两部分组成,第一部分使用了sigmoid激活函数,输出为,第二部分使用了tanh激活函数,输出为, 两者的结果后面会相乘再去更新细胞状态。
- SIGMOD层决定什么值需要更新。
- Tanh层创建一个新的候选值向量$c_{(t)}$
- 第二步还是为状态更新做准备。
数学表达式:
其中$W_i,U_i,b_i,W_a,U_a,b_a$,为线性关系的权重项和偏置项,σ为SIGMOD激活函数。
更新细胞
在研究LSTM输出门之前,我们要先看看LSTM之细胞状态。前面的遗忘门和输入门的结果都会作用于细胞状态 C(t),我们来看看细胞如何从C(t−1)到C(t):
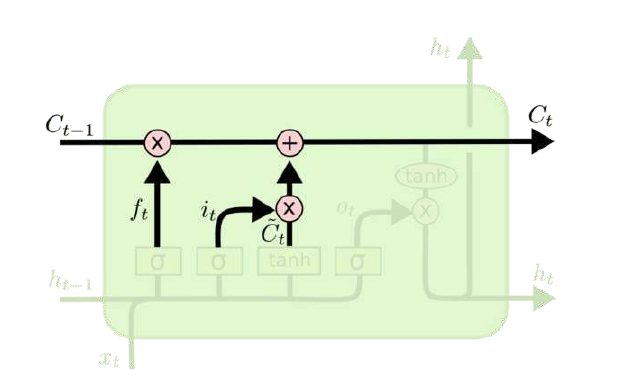
由图可知:细胞状态由两部分组成;第一部分是和遗忘门输出的乘积,第二部分是输入门的的乘积,总结为如下三点:
- 更新。
- 把和$f_{(t)}$相乘,丢弃掉我们确定需要丢弃的信息。
- 加上$i(t) * \tilde c_{(t)}$。最后得到新的候选值,根据我们决定更新每个状态的程度进行变化。
数学表达式:
其中,⨀为Hadamard积.
输出门
有了新的隐藏细胞状态C(t),我们就可以来看输出门了,子结构如下:
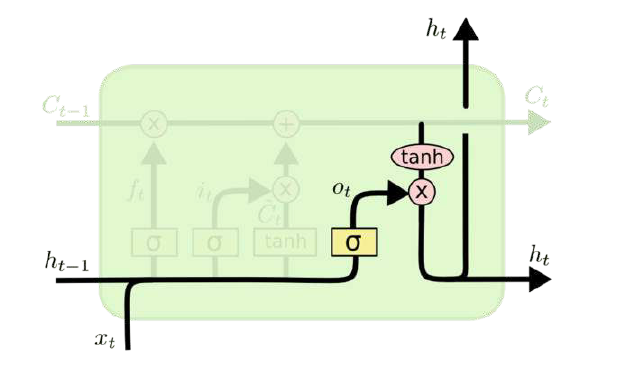
从图中可以看出:隐藏状态的更新由两个部分组成:第一部分是,它是由上一序列的隐藏状态和本序列的,以及激活函数SIGMOD得到的,第二部分是由隐藏状态激活函数组成,即:
- 最开始先运行一个SIGMOD层来确定细胞状态的哪个部分将输出。
- 接着用tanh处理细胞状态(得到一个-1到1之间的值),再将它和SIGMOD门的输出相乘。输出我们确定输出的那部分值。
数学表达式:
总结
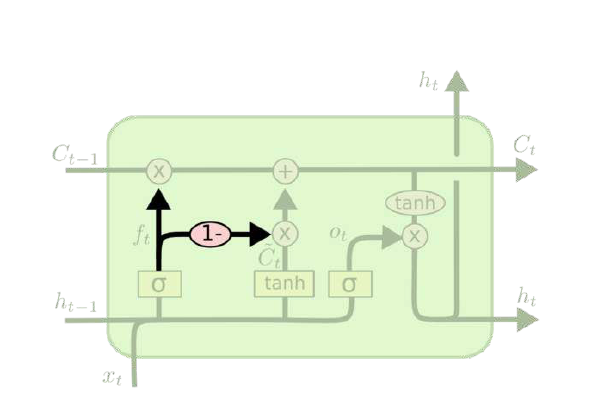
LSTM变体
- 增加
peephole connection - 让门层也会接受细胞状态的输入。
数学表达式:
- 通过使用
coupled忘记和输入门 - 之前是分开确定需要忘记和添加的信息,然后一同做出决定。
数学表达式:
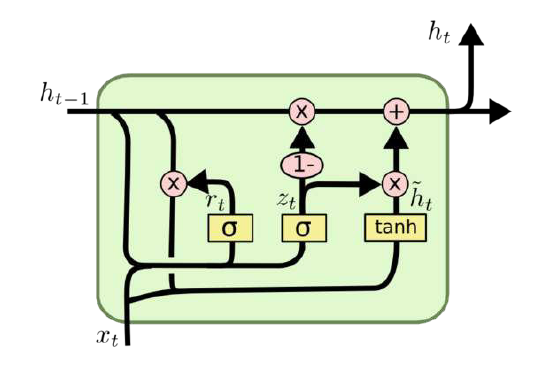
GRU
Gatad Reacurrent Unit (GRU),2014年提出。
- 将忘记门和输入门合成了一个单一的更新门
- 混合了细胞状态和隐藏状态
- 比标准的LSTM简单
数学表达式:
LSTM总结

实现
LSTM
|
GRU
|