目标
广告显示:只显示相关的广告
背景:
– 用户喜欢相关的广告
– 只有用户点击时,广告平台才能收到广告费
所以预测一个广告是否会被点击很关键
方式:
– 预估点击率 (predict Click Through Rate, pCTR)
推荐系统 vs. 点击率预估

CTR的挑战
• 用最少的资源在大量的数据上训练大量的模型
上亿的特征数目(模型系数的数目)
每天有上亿的流量(提供上亿次预测服务)
上亿的训练样本数目
• 其他
正负样本数目不均衡
面向稀有事件的 Logistic Regression 模型校准
特征稀疏(OneHot编码)
CTR预估
• 预测模型:预估广告是否被点击,是一个两类分类问题
• 特征:用户、广告、场景、媒体
• 性能评估:准确率/召回率、AUC
基础特征
展示广告:在某场景下,通过某媒体向用户展示广告
– 场景:当时场景,如何时何地,使用何种设备,使用什么浏览器等
– 广告 - 广告主特征、广告自身的特征如campaign、创意、类型,是否重定向等
– 媒体 - 媒体(网页、app等)的特征、广告位的特征等
– 用户 - 用户画像、用户浏览历史、检索关键词等
特征工程
• 特征离散化
• 特征交叉
FM/FFM: 类别型 特征
OneHot编码后再组合
GBDT:用树的叶子节点索引作为样本特征
特征组合并特征离散化
• 特征选择:嵌入到模型
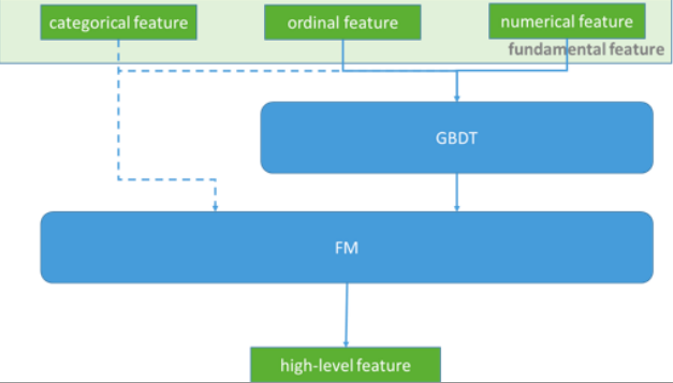
预测模型
• Logistic回归(LR):
– 特征工程很重要
– LR-FTRL: Google在2010年提出了一些理论基础,2013年给出了Paper,并且带有FTRL的实现伪代码。在此之后,FTRL才大规模应用在工业界。
• FM(Factorization Machines)
– Steffen Rendle于2010年提出Factorization Machines(FM),并发布开源工具libFM。凭借这单个模型,他在KDD Cup 2012上,取得Track1的第2名和Track2的第3名。本质上可看作是:高效特征交叉 + LR。
• 深度学习DNN
– 特征工程工作量少,但10^11 级别的原始广告特征、以及特征的稀疏性对DNN还是巨大挑战
CTR模型评估
• 原则上分类性能评价指标均可用于CTR模型评估
– Logloss、PR、…
• 最常用的评估指标:ROC曲线下的面积(Area Under Curve, AUC )
– 随机分类模型AUC为0.5
– 越接近1模型的效果越好
当随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。
AUC
• 当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变 ,AUC不变
• CTR场景下,测试数据中的正负样本的分布可能随着时间变化而变化

CTR预估-Logistic回归(LR)

Logistic回归 + L1正则
由于CTR预估中特征维数非常高,我们希望得到稀疏解,利用L1正则,目标函数为

Google: Large scale LR model
• Ad Click Prediction A view from the trenches
– Google FTRL模型在点击率预估任务上的应用
• FTRL是L1正则的LR,但对模型训练进行了优化:
– 在线学习(Online Learning)
– 模型稀疏
• 很重要,因为CTR问题中通常特征维数很高(上亿)
• 很稀疏(离散特征+OneHot 编码)
FTRL (Follow The Regulized Leader)
• 在批处理模式下,L1正则化通常产生稀疏模型
• 但Online中,每次权重向量的更新并不是沿着全局梯度进行下降,而是沿着某个样本的产生的梯度方向进行下降,整个寻优过程变得像是一个随机查找的过程,这样Online最优化求解即使采用L1正则化的方式,也很难产生稀疏解。
• 在线稀疏模:FTRL
– FTRL 综合了RDA和FOBOS,在L1范数或者其他非光滑的正则项下,能高效地得到稀疏解
FTRL
• FTRL和SGD是等价的。
• FTRL工程实现技巧(如节省内存等)请见原始论文。
• Tensorflow支持FRTL:FtrlOptimizer
性能:
L1-FOBOS、L1-RDA和L1-FTRL在一个小规模数据集(10^6 )上的性能

参考文献
[1] Convex function. http://en.wikipedia.org/wiki/Convex_function
[2] Lagrange multiplier. http://en.wikipedia.org/wiki/Lagrange_multiplier
[3] Karush–Kuhn–Tucker conditions. http://en.wikipedia.org/wiki/Karush-Kuhn-Tucker_conditions
[4] 冯扬. 并行逻辑回归 . http://blog.sina.com.cn/s/blog_6cb8e53d0101oetv.html
[5] Gradient. http://sv.wikipedia.org/wiki/Gradient
[6] Subgradient. http://sv.wikipedia.org/wiki/Subgradient
[7] Andrew Ng. CS229 Lecture notes. http://cs229.stanford.edu/notes/cs229-notes1.pdf
[8] Stochastic Gradient Descent. http://en.wikipedia.org/wiki/Stochastic_gradient_descent
[9] T. Hastie, R. Tibshirani & J. Friedman. The Elements of Statistical Learning, Second Edition: Data Mining,Inference, and Prediction. Springer Series in Statistics. Springer, 2009
[10] John Langford, Lihong Li & Tong Zhang. Sparse Online Learning via Truncated Gradient. Journal of Machine Learning Research, 2009
[11] John Duchi & Yoram Singer. Efficient Online and Batch Learning using Forward Backward Splitting. Journal of
Machine Learning Research, 2009
[12] Lin Xiao. Dual Averaging Methods for Regularized Stochastic Learning and Online Optimization. Journal of Machine Learning Research, 2010
[13] Convex Set. http://en.wikipedia.org/wiki/Convex_set
[14] H. Brendan McMahan & M Streter. Adaptive Bound Optimization for Online Convex Optimization. In COLT,2010
[15] H. Brendan McMahan. Follow-the-Regularized-Leader and Mirror Descent: Equivalence Theorems and L1 Regularization. In AISTATS, 2011
[16] H. Brendan McMahan, Gary Holt, D. Sculley, Michael Young, Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, Eugene Davydov, Daniel Golovin, Sharat Chikkerur, Dan Liu, Martin Wattenberg, Arnar Mar Hrafnkelsson, Tom Boulos, Jeremy Kubica, Ad Click Prediction: a View from the Trenches. In ACM SIGKDD, 2013
[17] Martin A. Zinkevich, Markus Weimer, Alex Smola & Lihong Li. Parallelized Stochastic Gradient Descent. In NIPS 2010
Facebook : GBDT+LR
• Practical Lessons from Predicting Clicks on Ads at Facebook [1]
• 用GBDT编码特征,然后再用LR做分类
– GBDT可替代FM做特征编码
– LR可用FTRL代替
[1] Xinran He et al. Practical Lessons from Predicting Clicks on Ads at Facebook, 2014.
https://cloud.tencent.com/developer/article/1005052
动机
• 用LR做CTR预估时,需做大量的特征工程 (非线性特征)
– 连续特征离散化(+ One-Hot编码)
– 特征进行二阶或者三阶的特征组合
• 问题:
– 连续变量切分点如何选取?
– 离散化为多少份合理?
– 选择哪些特征交叉?
– 多少阶交叉,二阶,三阶或更多?
• GBDT:一举解决了上面的问题
– 确定切分点和切分数目不在是凭主观经验,而是根据信息增益/Gini指标
– 每棵决策树从根节点到叶节点的路径,会经过不同的特征,此路径就是特征组合,而且包含了二阶,三阶甚至更多(所以GBDT提取特征时层数不用太深)

如上图所示:
GBDT训练得到:
第一棵树有3个叶子结点
第二棵树有2个叶子节点
GBDT编码:对于一个输入样本点x,如果它在第一棵树最后落在其中的第3个叶子结点,在第二棵树里最后落在第1个叶子结点,则通过GBDT获得的新特征向量为[0, 0, 1, 1,0],向量中的前三位对应第一棵树的3个叶子结点,后两位对应第二棵树的2个叶子结点
实现
• xgboost:predict函数
– predict(data, output_margin=False, ntree_limit=0, pred_leaf=False, pred_contribs=False, approx_contribs=False)
• lightGBM: predict函数
– predict(data, output_margin=False, ntree_limit=0, pred_leaf=False, pred_contribs=False, approx_contribs=False)
xgb_feature = xgb.predict(dtv, pred_leaf = True)
GBDT+FM
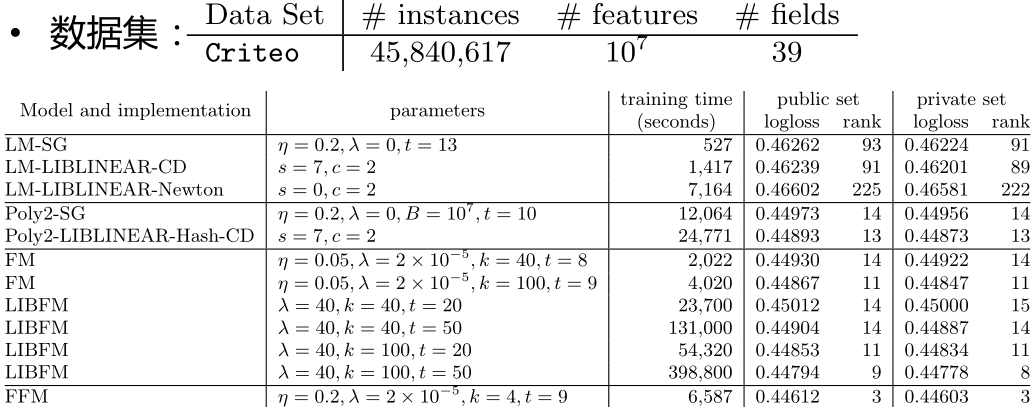
• Kaggle 2014年竞赛:Criteo Display Advertising Challenge
– https://www.kaggle.com/c/criteo-display-ad-challenge
• Rank1解决方案:3 idiot’s FM (FFM的发明者)

• Kaggle 2015年竞赛: Click-Through Rate Prediction
– https://www.kaggle.com/c/avazu-ctr-prediction
• Rank2解决方案:

为什么不直接用GBDT?
• 因为GBDT在线预测比较困难,而且训练时间复杂度高于LR。
• 所以实际中,可以离线训练GBDT,然后将该模型作为在线ETL的一部分。
Factorization Machines(FM)
• Steffen Rendle于2010年提出Factorization Machines[1],并发布开源工具libFM
(http://www.libfm.org/ )。
– 凭借这单个模型,他在KDD Cup 2012上,取得Track1的第2名和Track2的第3名。
• FM旨在解决稀疏数据的特征组合问题
– Recall:LR为线性模型,需要输入足够强的特征(特征组合)
[1] Steffen Rendle, Factorization Machines, Proceedings of the 10th IEEE International Conference on Data Mining (ICDM 2010), Sydney, Australia
数据稀疏
• CTR预估中很多类别型特征:例国家、节日
– 国家和节日为类别型特征 ,需要One Hot 编码
原始特征:

OneHot编码:

特征组合
某些特征经过关联之后,与label之间的相关性就会提高
例:将国家于假日组合:
“ USA”与“Thanksgiving”
“China”与“Chinese New Year”
这样的关联特征,对用户的点击有着正向的影响
来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,在“Thanksgiving”却不会有特别的消费行为。
更多示例:
• “化妆品”类商品与“女”性
• “球类运动配件”的商品与“男”性
二阶多项式模型

FM



模型训练

Field-aware Factorization Machines(FFM)



FFM的二次交叉项

FFM实现
• 作者提供C++版本实现: libffm
– https://github.com/guestwalk/libffm
实验结果
DNN for CTR
• Google: Deep wide DNN – Wide & Deep Learning for Recommender Systems
• FNN:– Deep Learning over Multi - field Categorical Data – A Case Study on User Response
Prediction
• PNN:– Product - based Neural Networks for User Response Prediction
• NFM– Neural Factorization Machines for Sparse Predictive Analytics
• Alibaba display ads: Deep interest network
– Deep Interest Network for Click - Through Rate Prediction
– Use attention - like network structure to model local activation of user interest to candidate
ad.
参考文献
1、http://blog.csdn.net/lilyth_lilyth/article/details/48032119
2、http://www.cnblogs.com/Matrix_Yao/p/4773221.html
3、http://www.herbrich.me/papers/adclicksfacebook.pdf
4、https://www.kaggle.com/c/criteo-display-ad-challenge
5、https://www.kaggle.com/c/avazu-ctr-prediction
6、https://en.wikipedia.org/wiki/Demand-side_platform
7、http://www.algo.uni-konstanz.de/members/rendle/pdf/Rendle2010FM.pdf
8、http://www.cs.cmu.edu/~wcohen/10-605/2015-guest-lecture/FM.pdf
9、http://www.csie.ntu.edu.tw/~r01922136/slides/ffm.pdf
10、https://github.com/guestwalk/libffm
11、https://en.wikipedia.org/wiki/Stochastic_gradient_descent#AdaGrad
12、http://openmp.org/wp/openmp-specifications/
13、http://blog.csdn.net/gengshenghong/article/details/7008704
14、https://kaggle2.blob.core.windows.net/competitions/kddcup2012/2748/media/Opera.pdf