支持向量机(SVM)
import numpy as np |
支持向量基本原理
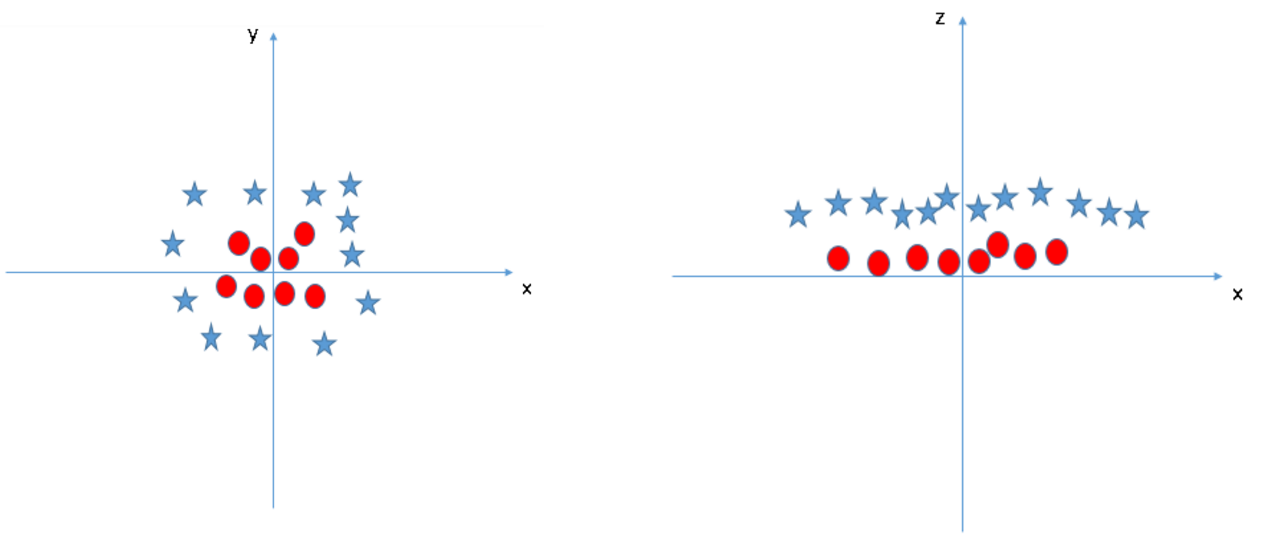
如何解决这个线性不可分问题呢?咱们给它映射到高维来试试
$z=x^2+y^2$
例子
#随机来点数据 |
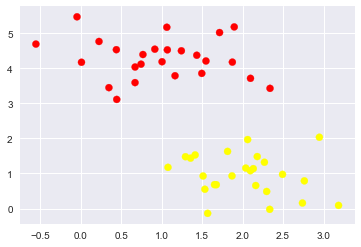
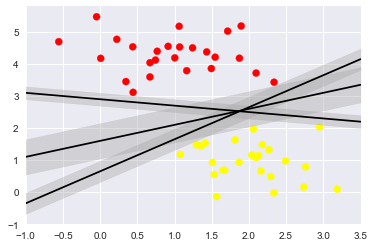
随便的画几条分割线,哪个好来着?
xfit = np.linspace(-1, 3.5) |
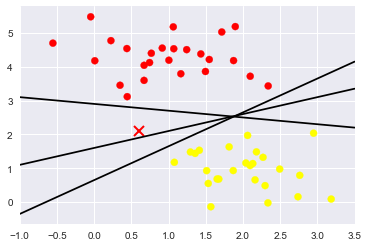
Support Vector Machines: 最小化 雷区
xfit = np.linspace(-1, 3.5) |
训练一个基本的SVM
from sklearn.svm import SVC # "Support vector classifier" |
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, |
#绘图函数 |
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn') |
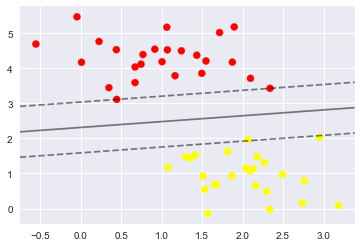
- 这条线就是我们希望得到的决策边界啦
- 观察发现有3个点做了特殊的标记,它们恰好都是边界上的点
- 它们就是我们的support vectors(支持向量)
- 在Scikit-Learn中, 它们存储在这个位置
support_vectors_(一个属性)
model.support_vectors_ |
array([[0.44359863, 3.11530945],
[2.33812285, 3.43116792],
[2.06156753, 1.96918596]])
- 观察可以发现,只需要支持向量我们就可以把模型构建出来
- 接下来我们尝试一下,用不同多的数据点,看看效果会不会发生变化
- 分别使用60个和120个数据点
def plot_svm(N=10, ax=None): |
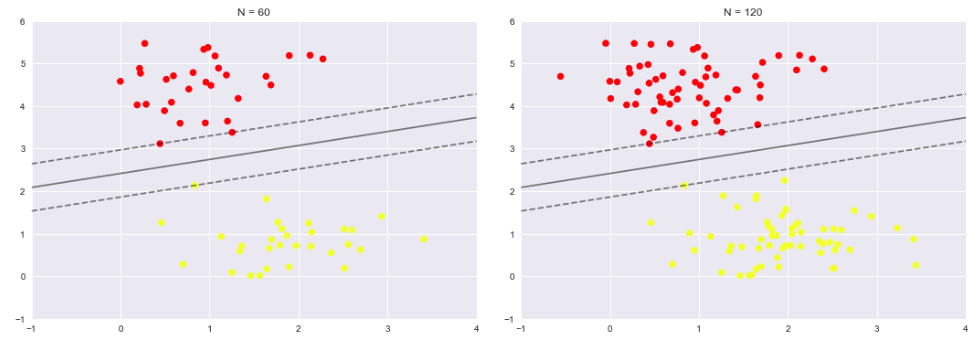
- 左边是60个点的结果,右边的是120个点的结果
- 观察发现,只要支持向量没变,其他的数据怎么加无所谓!
引入核函数的SVM
- 首先我们先用线性的核来看一下在下面这样比较难的数据集上还能分了吗?
from sklearn.datasets.samples_generator import make_circles |
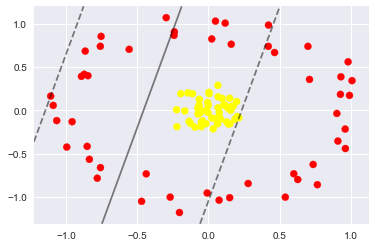
- 坏菜喽,分不了了,那咋办呢?试试高维核变换吧!
- We can visualize this extra data dimension using a three-dimensional plot:
#加入了新的维度r |
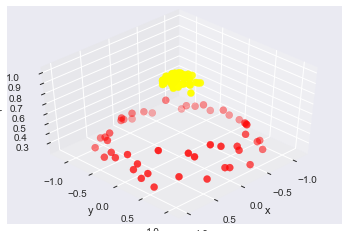
#加入基函数 |
SVC(C=1000000.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=’ovr’, degree=3, gamma=’auto’, kernel=’rbf’,
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='autumn') |
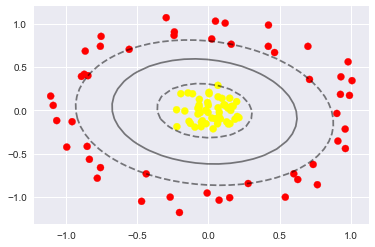
使用这种核支持向量机,我们学习一个合适的非线性决策边界。这种核变换策略在机器学习中经常被使用!
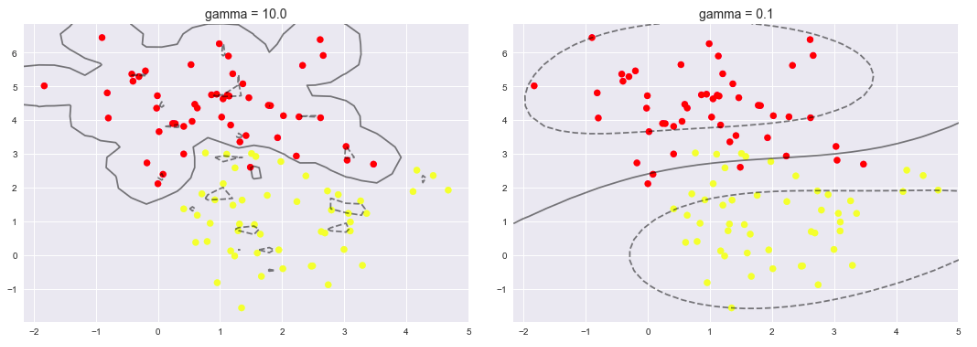
调节SVM参数: Soft Margin问题
调节C参数
- 当C趋近于无穷大时:意味着分类严格不能有错误
- 当C趋近于很小的时:意味着可以有更大的错误容忍
X, y = make_blobs(n_samples=100, centers=2, |
X, y = make_blobs(n_samples=100, centers=2, |
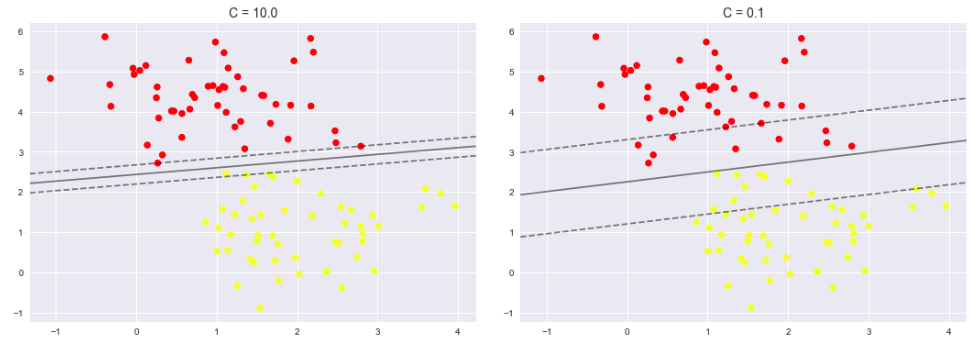
X, y = make_blobs(n_samples=100, centers=2, |
Example: Face Recognition
面部识别
from sklearn.datasets import fetch_lfw_people |
[‘Ariel Sharon’ ‘Colin Powell’ ‘Donald Rumsfeld’ ‘George W Bush’
‘Gerhard Schroeder’ ‘Hugo Chavez’ ‘Junichiro Koizumi’ ‘Tony Blair’]
(1348, 62, 47)
Let’s plot a few of these faces to see what we’re working with:
fig, ax = plt.subplots(3, 5) |

- 每个图的大小是 [62×47]
- 在这里我们就把每一个像素点当成了一个特征,但是这样特征太多了,用PCA降维一下吧!
from sklearn.svm import SVC |
from sklearn.model_selection import train_test_split |
使用grid search cross-validation来选择我们的参数
from sklearn.model_selection import GridSearchCV |
{‘svcC’: 5, ‘svcgamma’: 0.001}
model = grid.best_estimator_ |
(337,)
看看咋样吧!
fig, ax = plt.subplots(4, 6) |

from sklearn.metrics import classification_report |
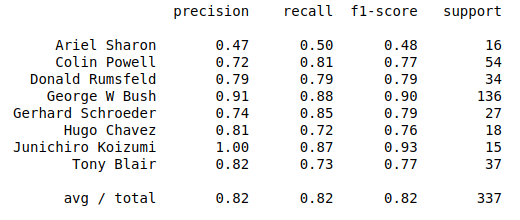
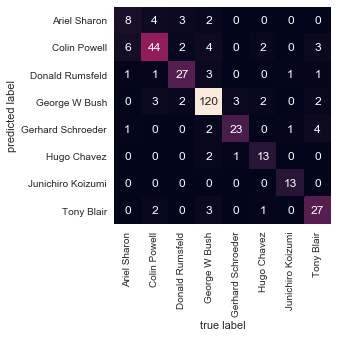
- 精度(precision) = 正确预测的个数(TP)/被预测正确的个数(TP+FP)
- 召回率(recall)=正确预测的个数(TP)/预测个数(TP+FN)
- F1 = 2精度召回率/(精度+召回率)
from sklearn.metrics import confusion_matrix |