推导表达式
得到一个元素为1到10的列表,可以怎么做?
列表
循环添加
方法一:
x = list(range(1,11)) |
方法二:
li = [] |
li |
这是我们前面所总结过的生成一个列表的方法。
列表推导
li = [i for i in range(1,11)] |
通过列表推导,精简了代码。
运行时间对比
import time |
list: 0.7910020351409912 |
可以看出列表推导的方式是比append方法更高效的,而list强制转换的是可能出现问题,所以总的来说就是推荐使用列表推导的方法。
列表推导+条件判断
l2 = [i for i in range(1,11) if i % 2 == 0] |
单独的if条件判断只能放在后面
列表推导+三目运算
l2 = [i if i % 2 == 0 else 0 for i in range(1,11)] |
如果是if+else的判断条件,就需要放前面。
集合
se = {i for i in range(1,11)} |
字典
li = list(range(1,11)) |
总结
推导表达式相对于for循环来处理数据,要更加的方便。
列表推导表达式使用更加的广泛。
迭代器和生成器
迭代器
列表推导是往列表中一个一个地放入数据,那如果一个一个地取出数据呢?
li = list(range(1, 11)) |
生成迭代器
迭代器对象
dir(list) |
迭代器对象本身需要支持以下两种方法,它们一起构成迭代器协议:
iterator.__iter__() |
取值
next(it) |
通过
next(iterator)
iterator.next()
来进行取值
注意:如果迭代器值取完之后,会返回 StopIteration 错误
自定义迭代器
class TupleIter: |
可以自己定义iter和next方法来自定义迭代器。
生成器
def func(n): |
迭代器提供了一个实现迭代器协议的简便方法
yield 表达式只能在函数中使用,在函数体中使用 yield 表达式可以使函数成为一个生成器
def func(end): |
通过生成器就生成了一个迭代器,通过dir(g)就能查出iter和next的方法。就比我们自定义迭代器更简单。
def func(end): |
|
yield 可以返回表达式结果,并且暂定函数执行
通过迭代器去生成斐波拉契数列要比直接得到更加节省内存。
总结:yield只能在函数里面使用。
模块
在另一个py文件中的对象如何导入到当前的py文件中呢?
模块
在python中,模块就是一个py文件,可以使用下面两种方法导入
import XX |
import datetime |
在同一目录下,可直接使用上面两种方法去导入;在不同目录下,需要使用 sys.path 添加路径
sys.path.append(‘path’)
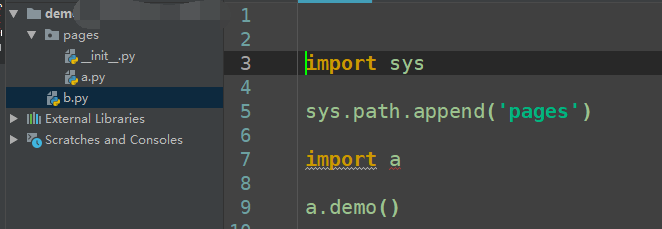
from pages import a |
不同的文件夹导入模块可以用这个两种方式。
在python3中导入后,会在当前路径下生成一个pycache 文件夹
sys模块
sys 模块提供了与python解释器交互的函数,在python中它是始终可以导入使用的.
sys.argv
import sys |
$ python b.py 123 456 |
获取终端命令行输入
sys.path
import sys |
解释器模块导入查找路径
if name == ‘ main’:
name
python会自动的给模块加上这个属性
如果模块是被直接调用的,则 name 的值是 main否则就是该模块的模块名
pages.a a |
注意
if name == ‘ main’: 该语句可以控制代码在被其他模块导入时不被执行
__main__ b |
包和包管理
如果模块太多了,怎么方便的去管理呢?
包概念
把很多模块放到一个文件夹里面,就可以形成一个包.
包管理
当把很多模块放在文件中时,为了方便引用包中的模块,引入了包管理
init.py
在包管理中,加入此模块,则包名可以直接通过属性访问的方式,访问此模块内的对象,此模块不加上可能不会报错,但是规范是要加上,文件内容可以为空
相对路径导入
在包管理中,可以通过. (一个点) 和 .. (两个点)分别来导入同层和上一层的模块
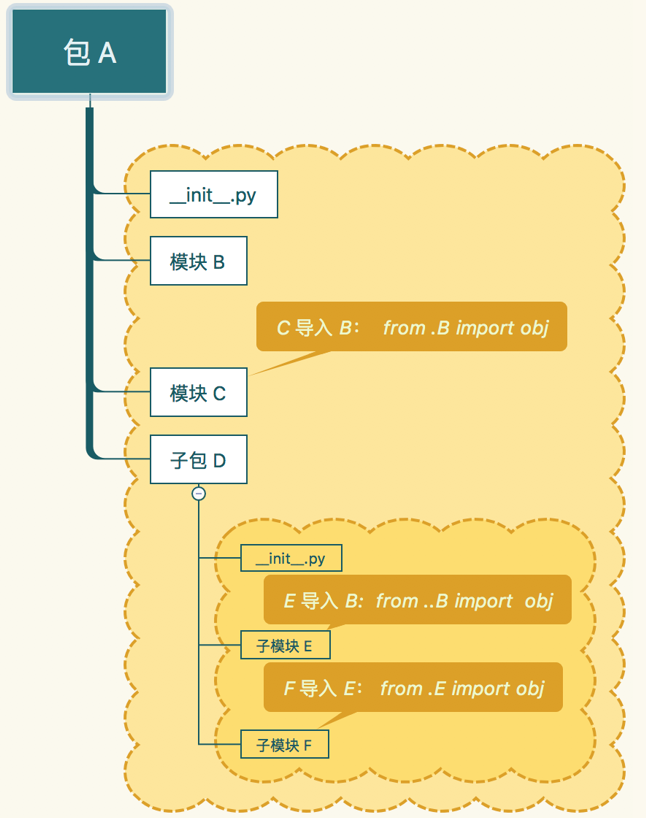
引入作用
在包中,如果包中模块要导入同一包中的其他模块,就必须使用此方法导入.
使用方法
from .module(..module) import obj (as new_name) |
引入之后的影响
当一个模块中出现此导入方式,则该模块不能被直接运行,只能被导入